CS441 Fall 2001
Project #1: Prolog, Mercury, and the Logic
Language Family
Adam Dang (ad056@umkc.edu)
Yenor
Liang (yol4b7@umkc.edu)
Sarah Wang (sw6bf@umkc.edu)
1. History of Prolog
Prolog (PROgramming LOGic) is a declarative logic programming language that
has become one of the most widely used languages for artificial intelligence
(AI). Prolog became a serious competitor to LISP because it represented a
fundamentally new approach to computing.
Early attempts at logic-based languages in the United States included
Micro-Planner and Conniver. Both attempts failed to replace LISP as an
artificial intelligence programming language because they were extremely
inefficient. Prolog grew out of work on natural language processing done by
Alain Colmerauer in Montréal and later in Marseille, and separate work on the
use of logic for programming by Robert Kowalski at Imperial College, London. It
was first implemented 1972 in ALGOL-W. Early collaboration between The
University of Aix-Marseille and Kowalski (who had moved to the University of
Edinburgh) continued until about 1975. The fact that Prolog overcame the
problems that bedeviled Micro-Planner and Conniver is due to Kowalski’s work on
the efficient implementation of Prolog.
Prolog is based on SLD (Selected Literal Definite) clause resolution, theorem
proving, and unification. The first versions had no user-defined functions and
no control structure other than the built-in depth-first search with
backtracking.
Early implementations included C-Prolog, ESLPDPRO, Frolic, LM-Prolog, Open
Prolog, SB-Prolog, UPMAIL Tricia Prolog. Currently, the most common Prologs in
use are Quintus Prolog, SICSTUS Prolog, LPA Prolog, SWI Prolog, AMZI Prolog, SNI
Prolog.
2. Overview
of Prolog
Logical programming
represents an effort by computer science to free the programmer from "the
drudgery of memory management, stack pointers, etc.", and instead allow the
program designer to fully concentrate on describing the problem and the
properties of the correct answer. Languages used for logical programming belong
to the declarative paradigm: the program specifies a computation by giving the
properties of a correct answer. This is quite different from the more familiar
procedural paradigm where the program specifies a computation by saying how it
is to be performed. However, it should be noted that there is no well-defined
boundary between procedural and declarative paradigms. Procedural languages
commonly include logic testing capabilities, and declarative languages by
necessity provide some procedural features such as input/output facilities.
Prolog
is the most widely used VHLL (Very High Level Language), which clearly possesses
many characteristics of declarative languages. The Prolog compiler, not the
programmer, is responsible for translating a description of the problem and
solution into the low level instructions of whatever computer happens to host
the program. By allowing the programmer to model the logical relationships among
objects and processes, complex problems are inherently easier to solve, and the
resulting program is easier to maintain through its lifecycle. Given the
necessary facts and rules, Prolog will use deductive reasoning to solve many
programming problems. The Prolog programmer only needs to supply a description
of the problem and the ground rules for solving it. From there, the Prolog
system is left to determine how to find a solution. Because of this declarative
(rather than procedural) approach, well-known sources of errors such as loops
that carryout one too many or one too few operations are eliminated right from
the start. Prolog encourages the programmer to start with a well-structured
description of the problem, so that, with practice, Prolog can also be used as
both a specification tool, and the implementation vehicle for the specified
product.
Prolog uses facts and
rules. Apart from some initial declarations, a Prolog program essentially
consists of a list of logical statements, either in the form of facts, such as:
|
|
father
("John", "Mary") "John is the father to
Mary"
|

|
father
("John", "Sally") "John is the father to
Sally"
|
|
|
father
("John", "Sam") "John is the father to Sam"
|
|
|
mother
("Jeanette", "Mary") "Jeanette is the mother to
Mary"
|
|
|
mother("Mary",
"Tom") "Mary is the mother to Tom"
|
or in the form of
rules, such as :
|
|
sister
(X, Y) :- father(Z,X),
|
|
father(Z,Y).
"X and Y are sisters if they have the same father"
|
where X Y, Z are
variables, which are used to specify bindings between the different relations.
Variables can be any name starting with an uppercase letter.
Prolog can make
deductions. Given some goals, for example, to conditions:
|
|
Goal
father ("John", "Mary").
Prolog will answer
true because the goal matches the stored facts.
If variables are used in
the goals, Prolog will find values for the variables:
Prolog will answer
X="John" because it can look it up in the facts. There is no
difference between using facts and rules, for example if the goal is:
Prolog will answer
X="Sally" because "Sally" can satisfy the rule for sister.
Similarly, Prolog can use
its deductive ability to find all solutions to the problem:
Prolog will answer
|
|
X="Mary"
|
|
X="Sally"
|
|
|
X="Sam"
|
The solutions are
found through backtracking where all combinations are tried.
Another representative of
the declarative paradigm is Mercury, which is being developed in the
University of Melbourne, Australia. Mercury is a logic/functional programming
language, which combines the clarity and expressiveness of declarative
programming with advanced static analysis and error detection features. Its
highly optimized execution algorithm delivers efficiency far in excess of
existing logic programming systems, and close to conventional programming
systems. Mercury addresses the problems of large-scale program development;
allowing modularity, separate compilation, and numerous optimization/time
trade-offs.
Logic programming is
considered by some to be far superior to procedural programming. Among the
advantages of declarative languages are:
|
In Prolog
the number of program lines required to solve a given problem is typically
only a fraction of that required by a procedural programming language like
C or Pascal. This can reduce development costs considerably, and since the
code is easier to modify, ongoing maintenance costs are often lower as
well.
|
|
|
Easy
to Read - Easy to Modify - Easy to learn
|
Many of the
common programming errors in languages like C or Pascal -for example a
loop that iterates one too many times or an uninitialized variable - are
eliminated in Prolog. Prolog code can be thought of as a well-structured
problem specification, in addition to being executable. Such code is
easily read and easily modified when aspects of the domain in question
change.
|
|
|
Easy
Manipulation of Complex Data Structures
|
Working with
complex data structures like trees, lists or graphs, often means big and
complex programs managing allocation and deallocation of memory.
Procedures operating on such data structures are almost impossible to keep
up to date when the design of the data structure is changed. By contrast,
Prolog has a simple and elegant notation for recursively defining and
accessing such data structures, shielding the programmer from all details
of pointers and explicit storage management.
|
With such
impressive characteristics, it is not surprising that Prolog, Mercury and other
logic programming languages find solid following and support in the programming
and scientific communities.
3.
Handling of Data Objects in Prolog
Prolog
programs consist of collections of statements. All Prolog statements are
constructed from terms. The basic Prolog terms are
o
Integer - A
positive or negative number whose absolute value is less than some
implementation-specific power of 2.
o
Atom - A text
constant beginning with a lowercase letter
o
Variable -
begins with an uppercase letter or underscore (_)
o
Structure -
Complex terms. The general form is functor(parameter list). The functor is any
atom and is used to identify the structure and the parameter list can be any
list of atoms, variables or other structures.
Prolog
has two basic statement forms. These correspond to the headless and headed Horn
clauses of predicate calculus. The simplest form of headless Horn clause in
Prolog is a single structure, which is interpreted as an unconditional assertion
or fact.
The
syntax for a fact is
pred(arg1, arg2, … argN).
Where
pred - The name of the predicate
arg1, … - The arguments
N - The arity
. - The syntactic end of all Prolog clauses
For
example
female(shelley).
male(bill).
Father(bill, shelley).
The
other basic form of Prolog statement for constructing the database corresponds
to a headed Horn clause. This form can be related to a known theorem in
mathematics from which a conclusion can be drawn if the set of given conditions
is satisfied. If the antecedent (the right side of a clausal form proposition)
of a Prolog statement is true, then the consequent of the statement must also be
true. Headed Horn clauses are called rules because they state rules of
implication between propositions.
For
example
Ancestor(mary, shelley)
:- mother(mary, shelley).
States
that if mary is the mother of shelley, then mary is an ancestor of shelley.
In
Prolog, the statements for logical propositions, which are used to describe both
known facts and rules that describe logical relationships among facts, are
called goals, or queries.
For
example, we could have
man(fred).
To
which the system will respond either yes or no. The answer yes means that the
system has proved the goal was true under the given database of facts and
relationships. The answer no means that either the goal was proved false or the
system was simply unable to prove or disprove it.
Conjunctive
propositions and propositions with variables are also legal goals. When
variables are present, the system not only asserts the validity of the goal but
also identifies the instantiations of the variables that make the goal true.
For
example,
father(X, mike).
Can
be asked. The system will then attempt, through unification (see next
paragraph), to find an instantiation of X that results in a true value for the
goal.
To
prove that a goal is true, Prolog finds solutions by unification: binding a
variable to a value. For an implication to succeed, all goal variables on the
left side of :- must find a solution by binding variables from the clauses,
which are activated on the right side. Standard Prolog evaluates clauses from
left to right. When all clauses are examined and all goal variables are bound,
the goal succeeds. In other words:
Goalclause(Vg)
is true if clause1(V1) and … and clausem(Vm) are
true.
The
following table summarizes the unification process.
|
Variable & any
term
|
The variable will
unify with and is bound to any term, including another variable.
|
|
Primitive &
primitive
|
Two primitive
terms (atoms or integers) unify only if they are identical.
|
|
Structure &
structure
|
Two structures
unify if they have the same functor and arity and if each pair of
corresponding arguments unify.
|
But
if a variable can not be bound for a given clause, that clause fails. When any
clause fails, Prolog backtracks - it backs up in the goal to the reconsideration
of a previously proven subgoal. Backtracking gives Prolog the ability to find
multiple solutions to for a given query or goal.
Handling of
Data Objects - Comparison of Prolog and Mercury
·
Unlike Prolog,
Mercury supports additional constructs that declare type, mode, and other
constraints. Data types supported by the language include: integers, reals,
strings, and a very flexible record/union type; the standard library supports a
wide variety of collection types including arrays, lists, trees, maps, etc. The
three important additional features Mercury has over Prolog are Types, Modes and
Determinism.
·
Mercury is a
strongly typed language. Mercury's type system is based on many-sorted logic
with parametric polymorphism, very similar to the type systems of modern
functional languages such as ML and Haskell. Programmers must declare the types
they need and the type signatures of the predicates they define. Declaring the
type of a predicate specifies the sets of values from which the predicate
variables may be drawn. Mercury has a polymorphic type system and its standard
types include:
char
int
float
string - equivalent to Mercury's string type
list(int)
·
Mercury is a
strongly moded language. The programmer must declare the instantiation state of
the arguments of predicates at the time of the call to the predicate and at the
time of the success of the predicate. Currently only a subset of the intended
mode system is implemented. Declaring the modes of a predicate specifies which
of the variables are to be viewed as input parameters and which are to be viewed
as output parameters. The compiler will infer the mode of each call, unification
and other built-in in the program. It will reorder the bodies of clauses as
necessary to find a left to right execution order; if it cannot do so, it
rejects the program. Like type-checking, this means that a large class of errors
is detected at compile time.
·
Mercury has a
strong determinism system. Predicates in Mercury may fail, succeed once or
succeed more than once. The number of times a predicate should succeed is
specified by the determinism of the predicate. Declaring the determinism of a
predicate specifies how often it may succeed, if at all. For each mode of each
predicate, the programmer should declare whether the predicate will succeed
exactly once (det), at most once (semidet), at least once (multi) or an
arbitrary number of times (nondet). As with types and modes, determinism
checking catches many program errors at compile time.
·
Mercury handles
dynamic data structures not through Prolog's assert/retract but by providing
several abstract data types in the standard Mercury library that manage
collections of items with different operations and tradeoffs.
·
Mercury also
has a couple of differences in data-term from Prolog. The first one is that
double-quoted strings are atomic in Mercury, they are not abbreviations for
lists of character codes. The second is that Mercury provides several extensions
to Prolog's term syntax: Mercury terms may contain record field selection and
field update expressions, conditional (if-then-else) expressions, function
applications, higher-order function applications, lambda expressions, and
explicit type qualifications.
·
In Mercury,
syntactically, a data-term is just a term. A data-term is either a variable, a
data-functor, or a special data-term. A special data-term is a conditional
expression, a record syntax expression, a lambda expression, a higher-order
function application, or an explicit type qualification
4. Handling of
Sequence Control in Prolog
Prolog
has a built-in structure named trace that displays the instantiations of values
to variables at each step during the attempt to satisfy a given goal. Trace is
used to understand and debug Prolog programs.
The
tracing model describes Prolog execution in terms of four events:
1.
call, which
occurs at the beginning of an attempt to satisfy a goal
2.
exit, which
occurs when a goal has been satisfied
3.
redo, which
occurs when backtrack causes an attempt to resatisfy a goal
4.
fail, which
occurs when a goal fails.
Call
and exit can be related directly to the execution model of a subprogram in an
imperative language.
From
following example, you can tell how Prolog produces results by using trace mode.
Database
and traced compound goal:
likes(jake,
chocolate).
likes(jake,
apricots).
likes(darcie,
licorice).
likes(darcie,
apricots).
Trace.
Likes(jake,
X), likes(darcie, X).
(1)
1 call: likes(jake, _0)?
(1)
1 Exit: likes(jake, chocolate)
(2)
1 Call: likes(darcie, chocolate)?
(2)
1 Fail: likes(darcie, chocolate)
(1)
1 Redo: likes(jake, _0)?
(1)
1 Exit: likes(jake, apricots)
(3)
1 Call: likes(darcie, apricots)?
(3)
1 Exit: likes(darcie, apricots)
X
= apricots
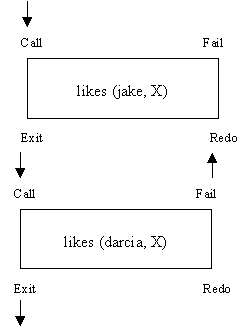
Consider
each goal as a box with four ports - call, fail, exit, and redo. Control enters
a goal in the forward direction through its call port. Control can also enter a
goal from the reverse direction through its redo port. Control can also leave a
goal in two ways: if the goal succeeded, control leaves through the exit port;
if the goal failed, control leaves through the fail port. A model of the example
above is shown in Figure 1.
Figure
1 - Control flow model for the goal likes(jake, X), likes(darcie, X)
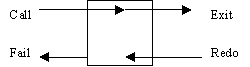
It
always succeeds the first time it is called, and it always succeeds on
backtracking. In other words, you can not backtrack through a repeat/0.
Figure 2 - Flow of control in the repeat built-in predicate
A
repeat/0 followed by some intermediate goals followed by a test condition will
loop until the test condition is satisfied. It is equivalent to a 'do until' in
other languages.
The
following command_loop/0 will simply read commands and echo them until end is
entered. The built-in predicate read/1 reads a Prolog term from the console. The
term must be followed by a period.
command_loop:-
repeat,
write('Enter command (end to exit): '),
read(X),
write(X), nl,
X = end.
The
last goal will fail unless end is entered. The repeat/0 always succeeds on
backtracking and causes the intermediate goals to be re-executed.
We
can execute it by entering this query.
?- command_loop.
- Recursive
control structure
Because
logical variables cannot have their values changed by assignment, the commands
must take two arguments representing the old state and the new state. The
repeat-fail control structure will not let us repeatedly change the state in
this manner, so we need to have a recursive control structure that recursively
sends the new state to itself.
In
Prolog, recursion occurs when a predicate contains a goal that refers to itself.
Every time a rule is called, Prolog uses the body of the rule to create a new
query with new variables. Since the query is a new copy each time, it makes no
difference whether a rule calls another rule or itself.
A
recursive definition always has at least two parts, a boundary condition and a
recursive case. The boundary condition defines a simple case that we know to be
true. The recursive case simplifies the problem by first removing a layer of
complexity, and then calling itself. At each level, the boundary condition is
checked. If it is reached the recursion ends. If not, the recursion continues.
For
example
The
following predicates tell us the first object is contained in second object.
location(envelope, desk).
location(flashlight, desk).
location(desk, office).
location(stamp, envelope).
location(key, envelope).
Now,
we need to find out
?- location(flashlight, office).
Even
predicate tells us the flashlight is in the desk and the desk is in the office,
but it does not indicate that the flashlight is in the office.
Using
recursion, we will write a new predicate, is_contained_in/2, which will dig
through layers of nested things, so that it will answer 'yes' if asked if the
flashlight is in the office.
We
can state a two-part rule which can be used to deduce whether something is
contained in (nested in) something else.
o
A thing, T1, is
contained in another thing, T2, if T1 is directly located in T2. (This is the
boundary condition.)
o
A thing, T1, is
contained in another thing, T2, if some intermediate thing, X, is located in T2
and T1 is contained in X. (This is where we simplify and recurse.)
The
first rule translates into Prolog in a straightforward manner.
is_contained_in(T1,T2) :- location(T1,T2).
The
recursive rule is also straightforward. Notice that it refers to itself.
is_contained_in(T1,T2) :- location(X,T2), is_contained_in(T1,X).
Then
try it.
?- is_contained_in(X, office).
X = desk ;
X = computer ;
X = flashlight ;
X = envelope ;
X = stamp ;
X = key ;
no
?- is_contained_in(envelope, office).
yes
How Recursion
Works
As
in all calls to rules, the variables in a rule are unique, or scoped, to the
rule. In the recursive case, this means each call to the rule, at each level,
has its own unique set of variables. So the values of X, T1, and T2 at the first
level of recursion are different from those at the second level.
However,
unification between a goal and the head of a clause forces a relationship
between the variables of different levels. Using subscripts to distinguish the
variables, and internal Prolog variables, we can trace the relationships for a
couple of levels of recursion.
First,
the query goal is
?- is_contained_in(XQ, office).
The
clause with variables for the first level of recursion is
is_contained_in(T11, T21) :-
location(X1, T21),
is_contained_in(T11, X1).
When
the query is unified with the head of the clause, the variables become bound.
The bindings are
XQ = _01
T11 = _01
T21 = office
X1 = _02
Note
particularly that XQ in the query becomes bound to T11 in the clause, so when a
value of _01 is found, both variables are found.
With
these bindings, the clause can be rewritten as
is_contained_in(_01, office) :-
location(_02, office),
is_contained_in(_01, _02).
When
the location/2 goal is satisfied, with _02 = desk, the recursive call becomes
is_contained_in(_01, desk)
That
goal unifies with the head of a new copy of the clause, at the next level of the
recursion. After that unification the variables are
XQ = _01 T11 = _01 T12 = _01
T21 = office T22 = desk
X1 = desk X2 = _03
When
the recursion finds a solution, such as 'envelope,' all of the T1s and X0
immediately take on that value.
Handling of
Sequence Control - Comparison of Prolog and Mercury
·
Because Mercury
is purely declarative, the goal `Goal, fail'
is interchangeable with the goal `fail,
Goal'. Also
because it is purely declarative, there are no side effects to goals. As a
consequence of these two facts, it is not possible to write failure driven loops
in Mercury. Neither is it possible to use predicates such as assert or retract.
However, all these can be done in Prolog. Failure driven loops in Prolog
programs is similar to the ordinary tail recursion in Mercury.
·
ISO Prolog
provides call/1, but there is no call/N (N>1). Most Prolog systems implement
call/1 quite inefficiently, and the calls to univ/2 and append/3 make call/N
even less efficient. Mercury provides a reasonably efficient call/1 and call/N
(N>1). As a convenience, Mercury also provides lambda expressions, so that
programmers can write a higher-order term without resorting to using an
auxiliary predicate.
·
Input and
Output control - Mercury is a purely declarative language. Therefore it cannot
use Prolog's mechanism for doing input and output with side effects. The
mechanism that Mercury uses is the threading of an object that represents the
state of the world through the computation. The type of this structure is `io__state'.
The modes of the two arguments that are added to calls are `di' for "destructive input" and `uo'
for "unique output''. The first means that the input variable must be the
last reference to the original state of the world, and that the output variable
will be the only reference to the state of the world produced by this predicate.
Predicates
that do input or output must have these arguments added.
For
example the Prolog predicate:
write_total(Total) :-
write('The total is '),
write(Total),
write('.'),
nl.
In
Mercury becomes
:- pred write_total(int, io__state, io__state).
:- mode write_total(in, di, uo) is det.
write_total(Total, IO0, IO) :-
print("The total is ", IO0, IO1),
print(Total, IO1, IO2),
print('.', IO2, IO3),
nl(IO3, IO).
One
of the important consequences of the model for input and output is that
predicates that can fail may not do input or output. This is because the state
of the world must be a unique object, and each IO operation destructively
replaces it with a new state. Since each IO operation destroys the current state
object and produces a new one, it is not possible for IO to be performed in a
context that may fail, since when failure occurs the old state of the world will
have been destroyed, and since bindings cannot be exported from a failing
computation, the new state of the world is not accessible.
In
some circumstances, Prolog programs that suffer from this problem can be fixed
by moving the IO out of the failing context. For example
...
( solve(Goal) ->
...
;
...
),
...
where
`solve(Goal)'
does some IO can be transformed into valid Mercury in at least two ways. The
first is to make `solve'
deterministic and return a status:
...
solve(Goal, Result, IO6, IO7),
( Result = yes ->
...
;
...
),
...
The
other way is to transform `solve' so that all the input and output takes place outside it:
...
io__write_string("calling: ", IO6, IO7),
solve__write_goal(Goal, IO7, IO8),
( solve(Goal) ->
io__write_string("succeeded\n", IO8, IO9),
...
;
IO9 = IO8,
...
),
...
o
Recursive
Control - Prolog code is written in a way that traverses the input list
left-to-right, appending elements to the tail of a difference list to produce
the output. However, Mercury code traverses the input list right-to-left and
constructs the output list bottom-up rather than top-down. It is tail-recursive
on the first recursive call, not the second one.
In
most circumstances, the need for difference lists is negated by the simple fact
that Mercury is efficient enough for them to be unnecessary.
o
Prolog uses
assert and retract methods to achieve goals. But Mercury has a standard library
which includes modules for lists, stacks, queues, priority queues, sets, bags
(multi-sets), maps (dictionaries), random number generation, input/output and
filename and directory handling to manipulate its execution behavior. The
implementation section must contain definitions for declarations, functions,
predicates, and sub-modules exported by the module.
For
example, here is the definition of a simple module for managing queues:
:- module queue.
:- interface.
% Declare an abstract data type.
:- type queue(T).
% Declare some predicates which operate on the abstract data type.
:- pred empty_queue(queue(T)).
:- mode empty_queue(out) is det.
:- mode empty_queue(in) is semidet.
:- pred put(queue(T), T, queue(T)).
:- mode put(in, in, out) is det.
:- pred get(queue(T), T, queue(T)).
:- mode get(in, out, out) is semidet.
:- implementation.
% Queues are implemented as lists. We need the `list' module
% for the declaration of the type list(T), with its constructors
% '[]'/0 % and '.'/2, and for the declaration of the predicate
% list__append/3.
:- import_module list.
% Define the queue ADT.
:- type queue(T) == list(T).
% Declare the exported predicates.
empty_queue([]).
put(Queue0, Elem, Queue) :-
list__append(Queue0, [Elem], Queue).
get([Elem | Queue], Elem, Queue).
:- end_module queue.
Prolog offers two fundamentally different ways of data representation.
Structured Terms are used when data structure needs to be passed between
procedures. Another way to represent data is as the Set of Facts. The
choice of which representation to use can affect the procedures needed in order
to search and manipulate, which, in turn affects the subprograms and how they
are handled in memory. When representing data as structured terms, structures
can get large, demanding more memory, and finding them can become tedious.
Here is an example of the use of structures in Prolog. A database of books in
a library contains facts of the form:
book(CatalogNumber, Title, author(FamilyName, GivenName)).
member(MemberNumber, name(FamilyName, GivenName), Address).
loan(CatalogNumber, MemberNumber, BorrowDate, DueDate).
A member of the library may borrow a book. When this is done, a "loan" is
entered into the database recording the catalogue number of the book that was
borrowed and the number of the member who borrowed it. The date at which the
book was borrowed and the due date are also recorded. Dates are stored as
structures of the form date(Year, Month, Day). For
example:
represents 16 June 1986. Names and address are all stored as character
strings (i.e. atoms).
The programmer must write separate procedures to search the structures to
find the desired items. For example, the program that will determine which books
a member has borrowed will be as follows:
|
has_borrowed(MemberFamilyName, Title, CatalogNumber):-
member(MemberNumber,name(MemberFamilyName,_), _),
loan(CatalogNumber, MemberNumber, _, _),
book(CatalogNumber, Title, _).
|
When dealing with large or variable length terms, such as list or trees, the
structure becomes very large and complex. If someone wants to search for an
element in the structure, then it would be very inefficient to write a retrieval
process simply based on matching because subprocedures would be needed to search
substructures. The advantage of using structures, however, is that when
searching them, the programmer does not have to worry about whether an item is a
variable that has been bound to a structure or whether it is a structure itself.
Prolog's pattern matching does this automatically.
Furthermore, there are two different ways in which the different elements of
these structures are bound during a procedure that directly affects the memory
management. These methods are structure copying (SC) and structure sharing (SS).
SS represents a structure instance by a two-pointer molecule with one to the
structure skeleton and the other to a binding environment. On the other hand, SC
makes a concrete copy of a structure whenever the structure is matched against a
variable. The space needed for copies is harder to determine than for structure
sharing and the number of copies being made depends on the pattern of the call.
The total amount of space used by copying is, on average, more efficient than
that used by structure sharing, except in the case where large terms need to be
copied. As far as efficiency in speed during a procedure, structure sharing is
faster in building new compound terms, but copying is faster in accessing those
terms. SS was used in earlier Prolog implementations while SC has been accepted
as the de facto standard in modern Prolog implementations.
The second way to represent data is to use collections of facts. Here is a
collection of facts about a hypothetical computer science department:
|
lectures(jeff, 611).
lectures(ken, 621).
lectures(claude, 641).
lectures(graham, 642).
lectures(ken, 643).
studies(fred, 611).
studies(jack, 621).
studies(jill, 641).
studies(jll, 642).
studies(henry, 642).
studies(henry, 643).
year(fred, 1).
year(jack, 2).
year(jill, 2).
year(henry, 3).
|
Information will be loaded into memory as sets of clauses and then can be
dealt with logically. In this way, the programmer can rely on Prolog's database
retrieval mechanisms to do the searching. This is a more advantageous method in
respect to both subprocedures and storage management when dealing with large or
variable length terms such as lists or trees. Instead of writing more
subprocedures to explore deeper levels of structures, data structures can be
represented by using constants to indicate which facts are parts of which
structure. This would give a normalized representation to work with easily.
These two different representations take cuts in efficiency as compared to
other programming languages, but they contribute greatly to Prolog's vast
flexibility. In most other languages, data can be stored in arrays in which the
data can be accessed by an index. This is advantageous because it directly
relates with how the data is stored in physical memory. The computer can quickly
find the element by using simple address arithmetic. Prolog, however,
traditionally has needed more flexible structures and therefore does not support
the same storage ability for arrays as other languages. An indexing system can
be implemented that is similar to arrays, but since the storage of the Prolog
terms does not follow the same sequential storage, it is not promised to be a
quick retrieval. The benefits in flexibility, however, make it worth the cut in
efficiency. The two representations of data have already been discussed as well
as their advantages as related to subprocedures. Prolog allows the ability to
switch between different representations in order to make use of the different
advantages each one offers. This change in representation can be made by simply
changing the definitions of the predicates. This can be done in most programs
without many other additional modifications.
Comparison of
Subprograms and Storage Management in Mercury and
Prolog
Since Mercury compiler generates C code, memory management in Mercury largely
depends on memory management in C. Mercury passes pointers to memory,
dynamically allocated by C. The current Mercury implementation supports two
different methods of memory management: conservative garbage collection, or no
garbage collection. (With the latter method, heap storage is reclaimed only on
backtracking.)
Conservative garbage collection makes inter-language calls simplest. When
using conservative garbage collection, heap storage is reclaimed automatically.
Pointers to dynamically allocated memory can be passed to and from C without
taking any special precautions.
When using no garbage collection, programmer must be careful not to retain
pointers to memory on the Mercury heap after Mercury has backtracked to before
the point where that memory was allocated. Future Mercury implementations may
use non-conservative methods of garbage collection. For such implementations, it
will be necessary to explicitly register pointers passed to C with the garbage
collector. The mechanism for doing this has not yet been decided on. It would be
desirable to provide a single memory management interface for use when
interfacing with other languages that can work for all methods of memory
management, but more implementation experience is needed before we can formulate
such an interface.
Subprograms and Memory Management References
Campbell, J.A. Implementation of Prolog, Elis Horwood, 1985
Henderson, F., Conway, T., Somogy, Z., Jeffery, D., Schachte, P., Taylor, S.,
Speirs, C. 1995-2001. Mercury Language Reference Manual. University of
Melbourne. (http://www.cs.mu.oz.au/research/mercury/information/doc/reference_manual_13.html)
Hoffman, A., Sammut, C. 2000. COMP3411: Artificial Intelligence, course
notes, Introduction to Prolog. School of Computer Science and Engineering, The
University of New South Wales, Sydney, Australia (http://www.cse.unsw.edu.au/~cs3411/notes/prolog/intro.html)
Li, X. 1996, Structure Sharing and Structure Copying Revisited, Compulog Net
Meeting on Parallelism and Implementation Technology, Department of Computer
Science, Lakehead University, Thunder Bay, Canada (http://www.cs.nmsu.edu/lldap/jicslp/xi.html)
Sebesta, R. W. 1999. Concept of Programming Languages, 4th ed.
Addison-Wesley Publishing Company, Inc.
6. Handling
of Abstraction and Encapsulation in Prolog
An abstraction is a way
of representing a group of related objects by a single object, which
demonstrates their common characteristics and hides their differences. The two
major kinds of abstraction in programming languages are process abstraction
and data abstraction. The process abstraction is a method for abstracting out how
something is done leaving only a description of what is done. Prolog is
a computer programming language designed to solve problems that involve
objects and the relationship between objects. Abstraction is achieved by
nature of the language. However, Prolog is a declarative language and is
nonprocedural. The details of computation are not clearly specified in the
program. Rather, Prolog defines some rules about the objects and their
relationships. A good example of this is quick sort in Prolog:
First, we need to
introduce a Prolog data structure called list. Prolog uses square brackets to
delimit a list. A list is an ordered sequence of elements that can have any
length and separated by commas. Prolog also uses the notation [X|Y] to denote
a list with head X and tail Y and [] represents an empty list. We assume that
the goal sort(A,B) will succeed if objects A and B in the desired order, that
is, if A is less than B in some sense.
Second, According to the
definition of quicksort, we need to split a list consisting of head H and tail
T into two lists L and M such that:
- all
the elements of L are less than or equal to H.
- all
the elements of M are greater than H, and
- the
order of elements within L and M is the same as in [H|T]
|
The goal
statements showing above split relationship is described as below:
split(H, [A|X], [A|Y],
Z) :- A=< H, split(H, X, Y, Z).
split(H, [A|X], Y,
[A|Z]) :- A > H, split(H, X, Y, Z).
split(_,
[],[],[]).
|
Third, with the
goal of split relationship defined, the next step is to sort each list
recursively and append M onto the back of L. Let’s first define append:
append([], L, L).
append([X|L1], L2,
[X|L3]) :- append(L1, L2, L3).
Please note here, the
first statement of "append" specifies the boundary condition. It is
the base case in recursion. The goal of append(X, Y, Y) succeeds when Z is a
list constructed by appending Y to the end of X.
The last step is to
write the quicksort program:
|
quicksort([],[]).
quicksort([H|T],S)
:-
split(H, T, A, B),
quicksort(A, A1),
quicksort(B, B1),
append(A1,
[H1|B1}, S).
|
As we mentioned
before, another area of abstraction is data abstraction. A data abstraction in
a programming language is a mechanism which collects together (or
encapsulates) the representation and operation of a data type. In Prolog, all
statements are constructed from terms. A term can be a constant, variable, or
a structure. A structure is a single object, which consists of a collection of
other objects, called components. The components are grouped together into a
single structure, which hides the detail representation. A structure consists
of a functor and its components, which separated by commas. Here is a simple
example of structure:
|
book(title(X),
author(L, F))
|
The above
example is a structure called book, which has two components, a title and an
author. The component "author" is also a structure, which has two
components, a last name and a first name. It is also obvious that the
component "title" is a structure too. So the structure
"book" allows the grouping of related information (title, author,
etc) into one single object, instead of being treated as separate entities.
This is the concept of encapsulation.
Another meaning of
encapsulation in imperative languages is that users of the new type can not
manipulate data objects of the type except by use of explicitly defined access
operations. This concept does not apply in declarative languages such as
Prolog. The structure used in Prolog represents relations among objects. The
book structure above shows the relations among objects, namely title and
author and they are not bound to the types. The binding of a value to the
structure, called instantiation, only takes place to satisfy one complete
goal. Operations defined in imperative languages do not exist in Prolog.
Here is an example of
the structure "book" in Prolog. We can create a fact using a functor
called "own" like this:
|
own(john,
book(concepts_programming_languages, author(sebesta, robert))).
|
The structure
"book" is instantiated and binding of type also takes place. You can
ask if John owns any book by the author Robert Sebesta:
|
?-
own(john, book(X, author(sebesta, robert))).
|
The Prolog finds
a fact that matches the question; it prints out the object that the variables
now stand for:
|
X= concepts_programming_languages;
|
In above
example, no operations change the value of the structure "book". The
functor "own" only show the fact, the relationship between its
elements. The value of "book" is uninstantiated once the goal is
satisfied. So functor "own" can not change the value of its
elements. In Prolog, there are no equivalent operations as defined in
imperative languages.
Comparison of Abstraction and Encapsulation in Mercury and
Prolog
Mercury is different
from Prolog in the area of data abstraction. Mercury uses a module system. A
module can include one or more modules. Each module has a name as in
Each module has
an interface section starting with a declaration:
The interface
section includes entities that are exported by this module. Declarations for
types are visible to other modules that use or import this module.
Each module has an
implementation section starting with a declaration:
In the
implementation section, declarations for types are not visible to other
modules that use or import this module, and declarations are local to the
module. The implementation section must contain definitions for all abstract
data types, abstract instance declarations, functions, predicates, and
sub-modules exported by the module, as well as for all local types, type class
instances, functions, predicates, and sub-modules. A type whose name is
exported but whose definition is not, can be manipulated only by predicates in
the defining module; this is how Mercury implements abstract data types and
encapsulation.
Let’s also take a
close looks at user defined types in Mercury. Mercury introduces three kinds
of user-defined types, discriminated unions, equivalence types and abstract
types.
A derived type is
defined using
If the type
term is a functor with zero arguments, it names a monomorphic type. Otherwise,
it names a polymorphic type; the arguments of the functor must be distinct
type variables. The body term is defined as a sequence of
constructor definitions separated by semi-colons.
In discriminated unions,
type definition introduces a distinct type. For example,
|
:- type tree
---> empty
|
|
; leaf(int)
; branch(tree,
tree).
|
Integer in leaf
and tree in branch are distinct types.
Another kind of
user-defined type is the equivalence type. The equivalence type identifies
one type name with another. The following example shows that money
is just int:
The
last kind of user-defined type is the abstract type. The abstract type hides
its implementation. Here is an example,
|
:- module foo.
:-
interface.
:-
type t.
...
:-
implementation.
:-
type t == u.
|
The
module foo is introducing a type t and its implementation is hidden to other
modules. Other modules can use type t but the only ways to manipulate t is
through predicates defined in foo's interface. This is the concept of
encapsulation in Mercury.
Below
is an example of use of module to implement an array:
:- module array.
:- interface.
% Declare an abstract data type.
:- type array(T).
% Declare some predicates that operate on the abstract data type.
:- pred empty_array(array(T)).
:- mode empty_array(out) is det.
:- mode empty_array(in) is semidet.
:- pred put(array(T), T, array(T)).
:- mode put(in, in, out) is det.
:- pred get(array(T), T, array(T)).
:- mode get(in, out, out) is semidet.
:- implementation.
% Arrays are implemented as lists. We need the `list' module
:- import_module list.
% Define the array ADT.
:- type array(T) == list(T).
% Declare the exported predicates.
empty_array([]).
put(Array0, Elem, Array) :-
list__append(Array0, [Elem], Array).
get([Elem | Array], Elem, Array).
:- end_module Array.
The above-mentioned module
system and user-defined type declarations are not available in Prolog.
Reference:
- Bugrim,
A., Fabrizio, F., Feng, B., Holcomb, J., Sawa, F., Slomczynski, J. ,
Wise, W. , Kazic T. What are Logic Programming and Prolog? Klotho:
Biochemical Compounds Declarative Database, (http://www.ibc.wustl.edu/moirai/cs_magenta/prolog.html)
-
Howe, D. 2001. Free On-Line Dictionary of Computing, Imperial College
Department of Computing. (http://foldoc.doc.ic.ac.uk/foldoc/index.html
accessed 03/06/2001).
-
Hancox, P.J. 1998. SEM-242 Prolog and Logic Programming, world-wide web
course notes. School of Computer Science, University of Birmingham. (http://www.cs.bham.ac.uk/~pjh/prolog_course/se207.html,
accessed 3/06/2001).
- Sedlick,
D., 2000. Prolog Say What? Discussion., (http://www.franken.de/users/nicklas/das/papers/prolog_description/discussi.html
)
- Prolog
Development Center. Visual Prolog, How Does Prolog Differ from Other
Languages? (http://www.visual-prolog.com/viptechinfo/pdcindex.htm)
- Henderson,
F., Conway, T., Somogy, Z., Jeffery, D., Schachte, P., Taylor, S.,
Speirs, C. 1995-2001. Mercury Project. University of Melbourne. (http://www.cs.mu.oz.au/research/mercury/index.html).
- Becket, R. Mercury tutorialhttp://www.cs.mu.oz.au/research/mercury/tutorial/index.html
- Clocksin, W. F., Mellish, W. F. 1984. Programming
in Prolog. Springer-Verlag Berlin Heidelberg.
- Henderson, F., Conway, T., Somogy, Z., Jeffery,
D., Schachte, P., Taylor, S., Speirs, C. 1995-2001. Mercury Language
Reference Manual. University of Melbourne. http://www.cs.mu.oz.au/research/mercury/information/doc/reference_manual_toc.html
- Mercury project Website http://www.cs.mu.oz.au/research/mercury/index.html
- Pratt, T.W. 1984. Programming languages: design
and implementation. Prentice-Hall, Englewood Cliff, NJ
- Robert
W. Sebesta, Concepts of Programming Languages, fifth edition,
2001
- Adventure
in Prolog - Online Book http://www.amzi.com/AdventureInProlog/advfrtop.htm
- Mercury
Home Page http://sk.nvg.org/lang/lang.html